Mindaugas Zukas
April 12, 2012 ・ Sphinx
Sphinx in Action: Autocomplete
This is a post from a series of posts called "Sphinx in Action". See the whole series by clicking here.
Autocomplete provides suggestions as the user is typing in the search field. Everyone knows how it works, this is the first thing we see when using Google:
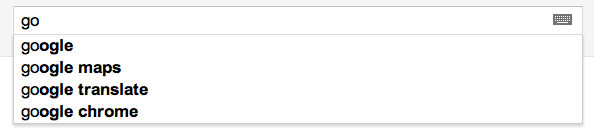
Many people like this and want it in their applications and Sphinx can be used to activate this functionality.
First, decide what things should be shown as suggestions. These can be:
-
Blog post titles or anything else that makes sense in your application
-
Previous/top user queries
-
Separate words from your dataset prepared with 'indexer --buildstops', or by other means
-
Anything else that works
We just need to gather the data we want to use in the autocomplete somewhere so it can be indexed by Sphinx or we can use Sphinx real time index to populate the autocomplete index (see below).
So once we have our suggestions data, we need to build the index. Many people find it difficult to do since Sphinx requires a unique id for each document and sometimes some documents don’t have ids or they can intersect if you want to merge them (eg. recent user queries or product names). We can handle this by using hashes instead of the ids. This can be crc32() if your autocomplete index is not very large or something else like half of md5() if your index is large enough to cause crc32() collisions.
The other thing we need to look at is how we will sort the suggestions. To do this, we can make a few attributes. We often use attributes such as suggestion length and suggestion word count (which can be easily calculated using the 'sql_attr_str2wordcount' directive). Here's an example:
source keyword {
sql_query = select crc32(name), name keyword, length(name) length from animals
sql_attr_uint = length
sql_field_string = keyword
sql_attr_str2wordcount = keyword_wc
...
}
index keyword {
source = keyword
path = keyword
docinfo = extern
min_prefix_len = 1
...
}
The problem with using the hash is we will most likely have difficulty finding the text by hash in the db, but we won't need this if we have all our strings set up right in the index using Sphinx string attributes (sql_field_string). There's another reason to do so - users attack this index more frequently than the others because each typed character will generate a query against Sphinx. Thus we need to optimize it to provide the best performance. We can accomplish this nicely by storing the strings in memory. This removes the need to look in the db, and consequently, it is very fast.
It is important to make sure we allocate enough memory for the index so Sphinx doesn't do unwanted reads from the disk:
index keyword {
...
mlock = 1
}
Now, all we need to do is query the index like this (or use other attributes to sort the results):
mysql> select keyword from keyword where match('^b*') order by keyword_wc asc, length asc limit 10 option max_matches=10, ranker=none;
+-----------+
| keyword |
+-----------+
| bee |
| bat |
| bear |
| boar |
| bison |
| beaver |
| buffalo |
| bush baby |
+-----------+
If we don't need to use text ranker (i.e. sorting by attributes is enough) we need to make sure to set 'ranker=none' option. This will improve performance.
It is good to apply the Sphinx real time index to autocomplete suggestions, because:
-
We won't need to rebuild this index if it is real time. We just need to insert into it in the same code we use to insert it into the db.
-
When we use last user queries we can insert them into the real time index only (unless you need it in the db as well).
Although the Sphinx real time indexes have a few disadvantages they're not very critical with respect to autocomplete. Since the index isn’t usually very big and we're going to store the strings in memory anyway, the difference – when compared to a non-real time index, will be even less significant in terms of resources consumption.
- Sphinx
- Basics