Mindaugas Zukas
March 22, 2011 ・ Sphinx
How to speed up Sphinx Real Time indexes up to 5-10 times
New type of index (Real Time) was released in Sphinx Search version 1.10.
Real Time (RT) indexes have many benefits compared to the plain indexes.
The most interesting ones are:
-
support of real time index update
-
support of MySQL protocol to manage indexes
-
support of string attributes
Sphinx Search is famous for its performance, so I decided to test search performance of RT indexes and compare it to the plain indexes.
The test server has 4Gb of RAM and 4 CPUs. I used Sphinx Search version 1.10.
The size of index data set was 1 million records. I ran 1000 queries and calculated the average response time for different configurations of the RT index and the Plain index.
The RT indexes configuration was tested with different chunk size values (this is rt_mem_limit option - RAM chunk size limit). The following configurations of RT indexes were tested:
-
rt_mem_limit = 2.5GB - blue bar
-
rt_mem_limit = 1GB - red bar
-
rt_mem_limit = 0.8GB - yellow bar
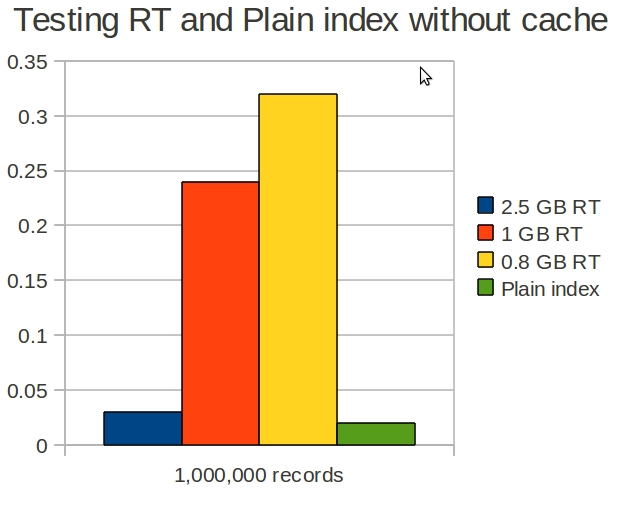
This is interestiong that the performance of 1GB and 0.8GB was very bad, but the performance of the 2.5 Gb index was quite similar to the Plain index. The reason why is because the structure of a chunk of Sphinx RT index is very similar to the structure of Sphinx plain index. In the test 2.5 GB memory was enough to fit all data in one chunk, that's why the performance of the 2.5 GB RT index was similar to the Plain index. The RT indexes with 1GB and 0.8GB have more than one chunk and this caused several times performance degradation.
When doing my tests I noticed that the queries to the small indexes are executed faster than those to the big ones. Therefore, I decided to split my 1 million docs index into 5 RT indexes (rt_mem_limit was set to 0.7Gb) each is 200 thousands docs. Using the distributed type of Sphinx index I joined all 5 parts into one.
This time I did two tests:
-
with empty cache - it means each query to the index was the first and unique
-
with cached queries - it means that each request has already been executed once, so Sphinx/OS already has it in cache
The results are:
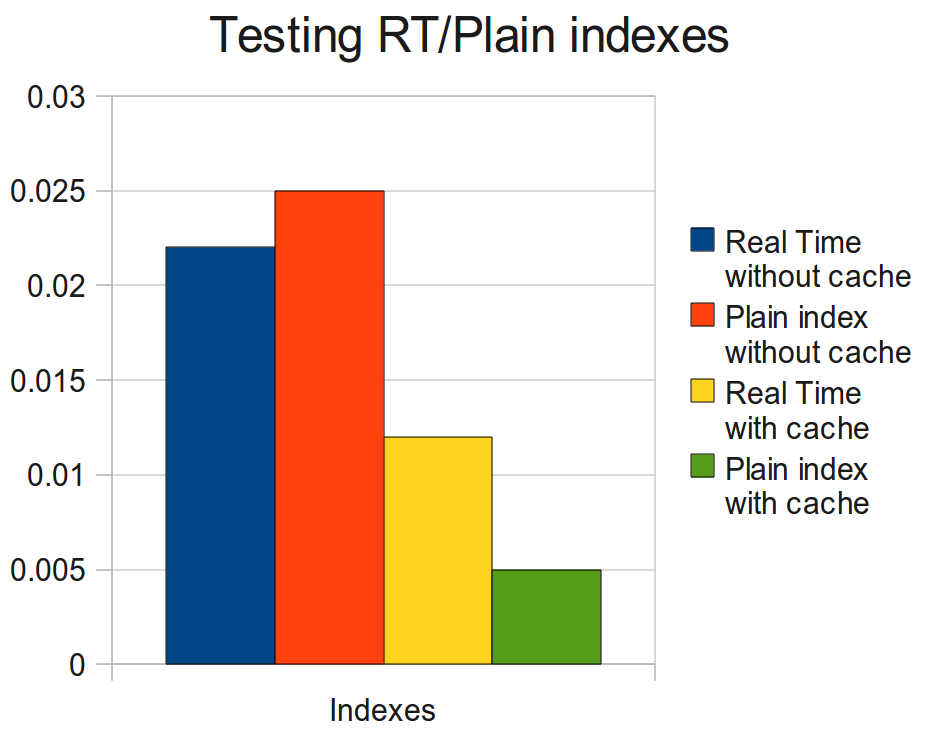
Results:
-
Non-cached queries against the RT index were performing a bit faster than in the Plain index (blue and red bars accordingly).
-
Cached queries against the Plain index were two times faster than against the RT index (green and yellow bars accordingly).
Conclusions:
-
If all indexed data fits into one chunk (rt_mem_limit is high enough) of Sphinx RT index, then the performance of the RT is the same as the Plain index.
-
Overall performance was improved up to 5-10 times by splitting one big RT index into 5 smaller parts.
-
Performance of RT indexes significantly depends on the number of chunks. The more chunks RT index has the slower its performance.
- Sphinx