Mindaugas Zukas
December 29, 2014 ・ Sphinx
Massive Indexing with Sphinx
Introduction
Imagine the following situation: multiple Sphinx daemons are serving huge amount of data running on numerous hardware servers. All indexes are based on the same servers with searchd daemons in order to minimize network data transfers. Request ratio is high, Sphinx servers are busy, but not overloaded. System as a whole is healthy. So far so good. And now you need to rebuild all these Sphinx indexes. That’s the point where the challenge comes.
The problem
Servers have limited performance - in terms of both CPU and I/O and are already running searchd daemons under significant load. Search requests ratio is high, maintenance downtime is not possible. Running indexer on the same server with searchd introduces additional load on the server which can easily saturate hardware server capabilities. Since searchd provides system’s key functionality we can’t allow performance degradation during indexation period - for hours and hours in total.
Problem Summary
-
Indexing requires significant amount of resources (CPU especially) and performing it on Sphinx servers affects production performance.
-
Management tends to be laborious and complex
- simple and straightforward
- limited scalability and maintenance complexity
What are we looking for?
Under such circumstances we are looking for decoupling of building indexes and serving indexes. Proof of concept solution would be producing indexes on several dedicated servers not involved directly in handling search requests and background-based distribution of result indexes on target Sphinx servers - preferably involving network shaping.
General solution features
-
Stand-alone indexing and
-
Results distribution over target servers
-
Ease of management
- scalability and flexibility
- complexity
Proposed solution - Distributed Indexer
Unified solution for Sphinx-based massive indexing. Key idea is to provide high-available and easy-to-use solution for scalable, decoupled massive indexing.
Distributed Indexer - components
As a distributed system running on multiple servers Distributed Indexer consists of several components, the most notable of which are workers, jobs and managers.
General schema:
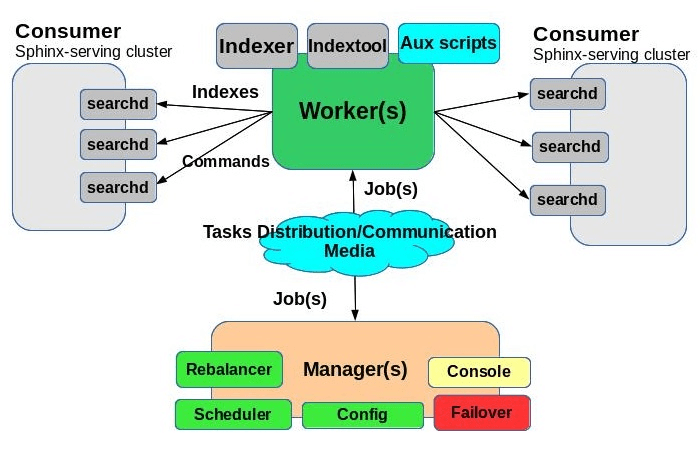
Main Components
Worker — daemon, running on indexing server, receives job from Managers, handles received job according to job description and reports result back to Managers. Typically workers would be counted by hundreds. In more depth replicated indexing process performed by workers is described here
Job — bundle including indexer configuration file and Sphinx configuration file. Job
description can contain calls to other applications within distributed Indexer or to
any other external application. Typical workflow of a job on a workers consists of the following parts:
-
Produce indexes
-
Check Indexes
-
Deliver results
-
Rotate sphinx
-
Hooks — external programs can be called at certain points and events
Manager — daemon, choreographing the whole distributed process. Consists of the following systems:
-
Scheduler — two types — «start at» and «countdown». Can be intermixed.
-
Console/Communication — via command console and command language
-
Failover — peer-to-peer failover between managers
-
Configuration parser
-
Auto-rebalancer
Good practice would be to have two Managers running on different servers in order to provide failover and neglect possible downtimes.
We’ve been using distributed indexer in production for some time now and can emphasize the following advantages:
-
Scalable solution. Adding new server to indexing pool is as easy as installing worker package. All the rest the system performs by itself. No hand-management of each indexation process is required. Launch worker, have indexes being built on the server.
-
Possible to utilize idling resources. Additional interesting feature is convenience in utilizing idling resources. In case you have underloaded servers with spare resources they can easily be involved in useful activities - building and distributing indexes. The same as previously - launch worker, have indexes being built on the server.
-
Automated rebalance. In order to spread requests load over the cluster evenly, we have to mix frequently and seldom requested data on servers. Since search queries tends to drift over the time, shifting point of popularity from one set of data to another and having new data added continuously, data intermixing have to be done periodically, on regular basis. Having this automated with distributed indexer helps admin team with routine tasks.
Real-World Numbers
Currently we have Distributed indexer running on 20 servers of which 2 are fully dedicated to distributed indexer and 18 are used partially in order to utilize idling resources. Around 1000 workers are launched on the system, building indexes constantly. Index build time varies from seconds up to several days for different indexes. Built indexes consume around 6T of disk space.
| Summary | | | ----------- | ---- | | Servers | 20 | | Workers | 1000 | | Disk | 6T |
Conclusion
Distributed Indexer presented itself as an easy-to-use massive Sphinx-based indexing solution having clear advantages and strong sides. The system is constantly evolving based on typical use-cases.
Related Reading
- Sphinx