Pavel Rykov
July 31, 2023 ・ Kubernetes
How to optimize Kubernetes performance for machine learning workloads
Introduction
Overview of Kubernetes
Kubernetes, also known as K8s, is an open-source platform designed to automate deploying, scaling, and operating application containers. It groups containers that make up an application into logical units for easy management and discovery. With its robust ecosystem and wide adoption, Kubernetes has become a de facto standard for container orchestration.
Importance of Kubernetes in Machine Learning
Machine learning (ML) workflows can be complex, resource-intensive, and require robust management systems. This is where Kubernetes comes into play. Kubernetes offers a platform that automates the deployment, scaling, and management of applications, which is particularly useful for ML workloads.
Some advantages of using Kubernetes for machine learning include:
-
Scalability: Kubernetes can automatically scale ML workloads up or down based on resource utilization. This enables you to make optimal use of your hardware resources.
-
Portability: Kubernetes supports multi-cloud and hybrid-cloud setups, allowing ML models to be trained and served on any infrastructure.
-
Manageability: Kubernetes provides robust tools for monitoring and logging, which are essential for managing ML workloads.
-
Versatility: With custom resources and operators, Kubernetes can be extended to support ML-specific needs, like GPU scheduling, distributed training, model versioning, etc.
It's worth noting that to fully leverage Kubernetes for machine learning workloads, you need to have a Kubernetes cluster up and running. If you're new to this, we've covered the steps to set up a simple Kubernetes cluster in a separate post: Installing a Simple Kubernetes Cluster Using Vagrant and VirtualBox.
Understanding and Managing Datasets in Kubernetes
Data Volume Management in Kubernetes
In Kubernetes, a Volume is a directory, possibly with some data in it, which is accessible to the Containers in a Pod. A Pod can use multiple volumes of different types simultaneously. This is necessary when, for instance, you have data that survives the lifecycle of a single Pod, or when you need to share data between Pods.
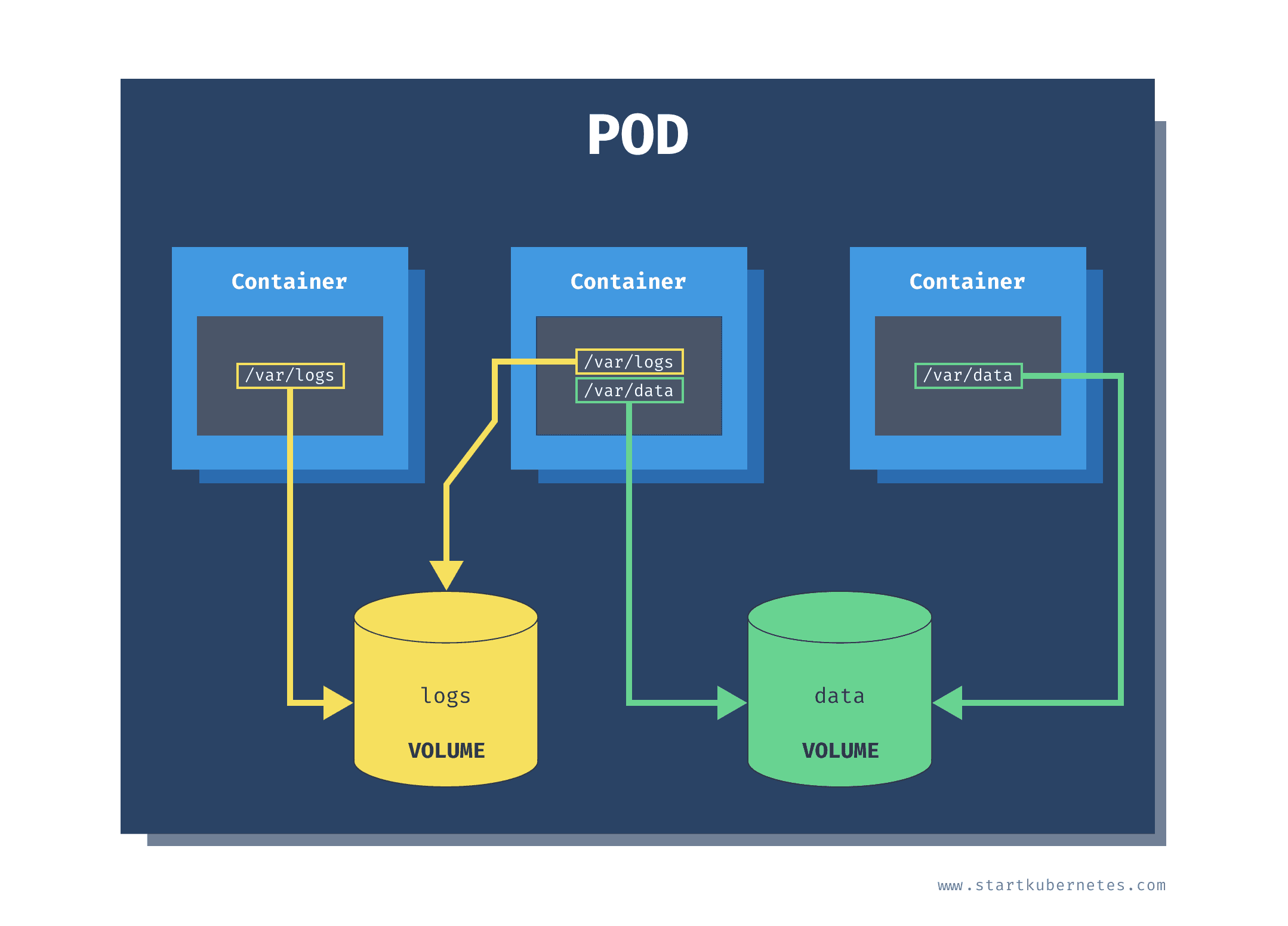
(Source: Exploring Kubernetes Volumes by Peter Jausovec)
Persistent Volume and Persistent Volume Claims
To manage storage in a way that is independent of Pods, Kubernetes provides the PersistentVolume (PV) and PersistentVolumeClaim (PVC) resources. A PV is a piece of storage in the cluster that has been provisioned by an administrator, while a PVC is a request for storage by a user. PVs and PVCs make it possible to consume storage resources without knowing the details of the particular cloud environment.
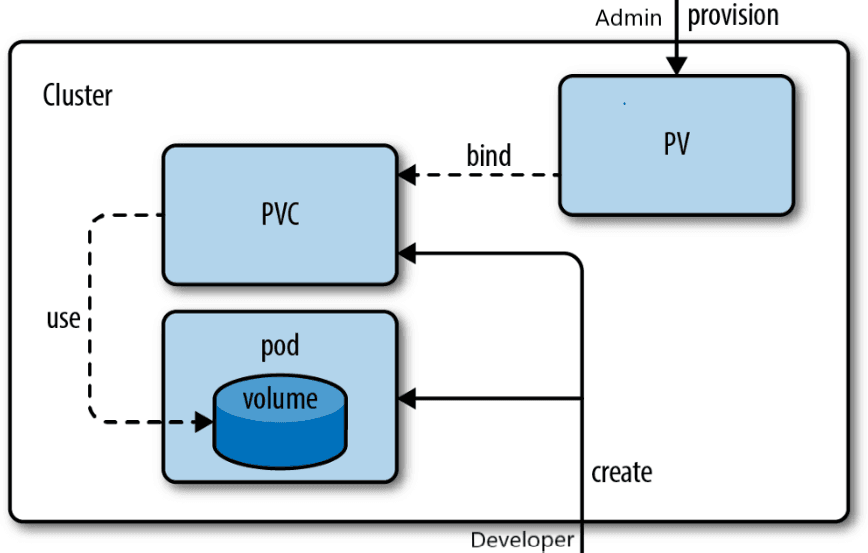
(Source: How to create PV and PVC in Kubernetes by Vikas Vashisth)
Optimizing Storage for Machine Learning Datasets
To optimize data storage for ML workloads, consider using a distributed file system like Ceph. Ceph can provide a scalable and resilient solution for handling large ML datasets. We've covered the steps to install Ceph and connect it to a Kubernetes cluster in a separate post: Installing Ceph as a Distributed Storage Solution and Connecting it to Kubernetes.
Here are some practices to follow:
-
Caching: Frequently used data can be cached to speed up access times. This is particularly useful in machine learning, where certain data, like a validation set, is used many times.
-
Data partitioning: Split the data into smaller chunks that can be processed independently. This allows for more efficient use of resources as different nodes can process different parts of the data simultaneously.
-
Parallel I/O operations: Use parallel I/O operations to speed up data loading times. This can often be achieved by using multiple worker threads for data loading.
Best Practices for Data Management in Kubernetes
When using Kubernetes for machine learning workloads, you should adhere to the following best practices for data management:
-
Use PVCs to request storage: This abstracts the details of the storage provisioning and lets you work with the data.
-
Delete PVCs when done: After the training is complete, delete the PVC to free up storage resources. However, be careful not to delete any data that you may need later.
-
Backup your data: Ensure that your data is regularly backed up. This can often be done automatically by the underlying storage system, like Ceph.
Training Neural Networks in Kubernetes
Using Kubernetes for Distributed Training
Kubernetes can efficiently orchestrate distributed training tasks due to its inherent ability to manage, scale, and deploy containers. By leveraging Kubernetes, you can run multiple instances of your training job in parallel, each on a different subset of your data. This way, you can train your neural network model on a large dataset in less time.
For example, consider a simple Python application using TensorFlow to train a neural network model:
import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# Specify the paths for the datasets and the model
train_dataset_path = os.path.join(os.environ['TRAIN_DATASET_PATH'], 'train_data')
test_dataset_path = os.path.join(os.environ['TEST_DATASET_PATH'], 'test_data')
model_path = os.path.join(os.environ['MODEL_PATH'], 'my_model.h5')
# Load datasets
train_dataset = keras.preprocessing.image_dataset_from_directory(
train_dataset_path,
validation_split=0.2,
subset="training",
seed=1337,
image_size=(64, 64),
batch_size=32,
)
test_dataset = keras.preprocessing.image_dataset_from_directory(
test_dataset_path,
validation_split=0.2,
subset="validation",
seed=1337,
image_size=(64, 64),
batch_size=32,
)
# Build and train the model
model = keras.Sequential([
keras.Input((64, 64, 3)),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(10, activation="softmax"),
])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_dataset, epochs=5)
# Save the trained model
model.save(model_path)
Content of requiremets.txt:
tensorflow==2.6.0
Next, let's create a Dockerfile for our application:
FROM tensorflow/tensorflow:2.6.0
WORKDIR /app
# Copy the requirements file
COPY requirements.txt .
# Install dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the code
COPY . .
CMD ["python", "/app/train_model.py"]
With the Dockerfile, we can build a Docker image and push it to a Docker registry. Assuming you're in the same directory as the Dockerfile and the Python script:
# Build Docker image
docker build -t myregistry/myimage:1.0 .
# Push Docker image to the registry
docker push myregistry/myimage:1.0
Now, let's create a Kubernetes Job that will run our training script in the cluster. The job will use a PersistentVolumeClaim (PVC) to access the training and test data from Ceph, and another PVC to store the trained model:
apiVersion: batch/v1
kind: Job
metadata:
name: train-model
spec:
template:
spec:
containers:
- name: train-model
image: myregistry/myimage:1.0
env:
- name: TRAIN_DATASET_PATH
value: /data/train
- name: TEST_DATASET_PATH
value: /data/test
- name: MODEL_PATH
value: /models
volumeMounts:
- name: dataset-volume
mountPath: /data
- name: model-volume
mountPath: /models
volumes:
- name: dataset-volume
persistentVolumeClaim:
claimName: ceph-dataset-pvc
- name: model-volume
persistentVolumeClaim:
claimName: ceph-model-pvc
restartPolicy: Never
backoffLimit: 4
In this YAML manifest, we're defining a Kubernetes Job that runs a container using our Docker image. The container has three environment variables: TRAIN_DATASET_PATH, TEST_DATASET_PATH, and MODEL_PATH. These variables are used in our Python script to locate the training and test data, and to store the trained model. The container has access to two volumes, one for the datasets and one for the model, which are backed by PVCs bound to Ceph volumes.
After creating the job manifest, you can apply it using kubectl:
kubectl apply -f train-model-job.yaml
This will create a new job in your Kubernetes cluster that will train the model using the data in the Ceph volumes and store the trained model back in Ceph.
Role of Kubernetes Operators in Neural Network Training
Kubernetes Operators are a concept introduced by CoreOS to extend the capabilities of Kubernetes. They act as custom controllers watching over the Custom Resource Definitions (CRDs). In simple terms, they are software extensions to Kubernetes that make use of custom resources to manage applications and their components.
In the context of neural network training, Kubernetes Operators can provide significant benefits:
-
Automated Training Jobs: Kubernetes Operators can automate the entire lifecycle of a neural network training job. They can handle the deployment of training jobs, manage their state, handle failure and recovery, and even schedule them based on custom policies. This automation reduces the manual effort required to manage training jobs and increases their reliability.
-
Custom Resource Definitions for ML Workloads: One of the primary advantages of Kubernetes Operators is the ability to define custom resources. For machine learning workloads, we can create custom resources that describe a training job. For instance, the Kubeflow project provides the TFJob CRD for running TensorFlow training jobs. This allows us to manage complex machine learning workloads just like any other Kubernetes application.
-
Integration with ML Libraries and Frameworks: Many Kubernetes Operators are designed to work seamlessly with popular machine learning libraries and frameworks such as TensorFlow, PyTorch, and MXNet. They understand the specific requirements and nuances of these frameworks and manage the training jobs accordingly. This feature allows data scientists to focus on developing models without worrying about the underlying infrastructure.
-
Advanced Scheduling Capabilities: Kubernetes Operators can take advantage of the advanced scheduling capabilities of Kubernetes. They can ensure that training jobs are scheduled on the appropriate nodes considering factors such as GPU availability, memory requirements, network latency, etc.
For instance, the Kubeflow project, an open-source machine learning platform built on Kubernetes, provides operators for TensorFlow (TFJob Operator) and PyTorch (PyTorchJob Operator). These operators extend Kubernetes to provide a native and seamless experience for running training jobs using these frameworks.
Let's consider an example of how you might use a Kubeflow's TFJob to train a TensorFlow model.
You would first define a TFJob YAML manifest:
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "tfjob-example"
spec:
tfReplicaSpecs:
PS:
replicas: 2
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: gcr.io/tf-operator/tf-job-operator:latest
Worker:
replicas: 4
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: gcr.io/tf-operator/tf-job-operator:latest
In this YAML manifest, we're defining a TFJob with two parameter servers (PS) and four workers. The image for the containers is the TensorFlow image.
After defining the TFJob, you would apply it using kubectl:
kubectl apply -f tfjob-example.yaml
The TFJob Operator would then create the necessary Kubernetes resources (pods, services, etc.) to run the training job. It would also monitor the status of the job and make adjustments as necessary, such as restarting failed pods.
To summarize, Kubernetes Operators play a critical role in neural network training. They provide the automation, customizability, and integration needed to manage complex machine learning workloads effectively. As such, they're an essential tool for any machine learning engineer working with Kubernetes.
Resource Allocation and Management for Training Jobs
In a Kubernetes cluster, proper resource allocation is critical for the efficient execution of applications. When it comes to machine learning workloads, this aspect becomes even more important due to the resource-intensive nature of these tasks.
To help in resource allocation, Kubernetes provides several mechanisms. Two of the most common ones are "requests" and "limits". These settings can be applied to both CPU and memory resources.
Requests: This is the amount of a particular resource that a container is guaranteed to get. If a container requests a resource, Kubernetes will only schedule it on a node that can give it that resource.
Limits: This is the maximum amount of a particular resource that a container can use. If a container goes above this limit, it will be throttled and can even be terminated.
In the context of machine learning workloads, setting appropriate requests and limits is crucial. For example, if a training job requires a high amount of CPU or memory, not setting a corresponding request may lead to the job being scheduled on a node that can't provide these resources, leading to slower training times or failures. On the other hand, setting a too high limit may lead to resource wastage.
Resource allocation can be set in the Kubernetes job YAML file. Here is an example:
apiVersion: batch/v1
kind: Job
metadata:
name: ml-job
spec:
template:
spec:
containers:
- name: ml-container
image: my_ml_image:latest
resources:
requests:
memory: "64Gi"
cpu: "16"
limits:
memory: "128Gi"
cpu: "32"
restartPolicy: OnFailure
In this example, the ML job requests 64Gi of memory and 16 CPU cores, with limits set to 128Gi and 32 cores, respectively. Kubernetes will attempt to schedule this job on a node that can satisfy these requests.
Furthermore, Kubernetes supports the allocation of GPUs to containers for machine learning tasks. This can be done using the nvidia.com/gpu resource name in the resource allocation.
Finally, it's worth noting that Kubernetes also provides Quality of Service (QoS) classes that are used to determine the scheduling and eviction policies. The QoS class of a Pod is determined based on whether the resource requests and limits are set and how they are set.
-
Guaranteed: If
limitsandrequestsare set and are equal for all resources, the pod is classified as Guaranteed. -
Burstable: If
requestsand optionallylimitsare set (but not equal), for one or more resources, the pod is classified as Burstable. -
BestEffort: If
requestsandlimitsare not set for any of the resources, the pod is classified as BestEffort.
By carefully managing resources and understanding the QoS classes, you can optimize your ML workloads in a Kubernetes environment.
Optimizing the Training Process
To optimize the training process, you can use techniques like hyperparameter tuning, model quantization, and pruning. Additionally, you can use Kubernetes features to optimize your training jobs. For example, you can take advantage of the Kubernetes Horizontal Pod Autoscaler, which automatically scales the number of pods in a deployment or replica set based on observed CPU utilization.
Also, you can use affinity and anti-affinity rules to influence how the Kubernetes scheduler assigns pods to nodes. For instance, if your training job benefits from fast inter-process communication, you might want to ensure that all pods of the job are scheduled on the same node (affinity). On the other hand, if your training job is memory-intensive, you might want to distribute the pods across nodes (anti-affinity) to avoid running out of memory on a single node.
Furthermore, it's crucial to monitor your training jobs to identify and resolve performance issues. Kubernetes provides various tools for monitoring and logging, such as Prometheus and Fluentd, which you can use to keep track of metrics like CPU and memory usage, network traffic, and disk I/O.
To conclude, training neural networks in Kubernetes involves a combination of machine learning techniques and Kubernetes features. By leveraging these, you can train your models more efficiently and effectively, thereby accelerating your machine learning projects.
In the next section, we will discuss how to deploy trained neural networks in Kubernetes.
Deploying Trained Neural Networks in Kubernetes
After you've trained your neural network model, the next step is to deploy it in a production environment where it can serve predictions. Kubernetes provides several features that can help you deploy, scale, and manage your trained models effectively.
Deploying machine learning models, especially trained neural networks, is a crucial step in the machine learning pipeline. It involves making the models available for use in other applications, services, or systems. Kubernetes offers a robust and flexible platform for deploying and managing these models.
Deploying Machine Learning Models with Kubernetes
The first step in deploying a trained neural network model with Kubernetes is to package the model into a Docker container. This container typically includes the model file (e.g., a .h5 file for a trained Keras model), along with the code and libraries needed to run the model.
You can use Flask, a lightweight web server framework in Python, to create a simple API for the model. This API will receive input data, run it through the model, and return the model's predictions.
Here is an example of a simple Flask app that serves a trained model:
from tensorflow.keras.models import load_model
from flask import Flask, request
import numpy as np
import json
# Загрузка обученной модели
model = load_model('/models/model.h5')
app = Flask(__name__)
@app.route("/predict", methods=['POST'])
def predict():
data = request.json
prediction = model.predict(np.array([data['input']]))
return json.dumps({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
This script loads a trained model from the /models directory and exposes a /predict endpoint that accepts POST requests with input data, makes a prediction using the model, and returns the prediction.
Here's an example requirements.txt for the Flask application shown above:
flask==2.0.1
numpy==1.21.0
tensorflow==2.5.0
Next, we'll create a Dockerfile to package this Flask application and our trained model into a Docker image. Here's an example Dockerfile:
FROM python:3.8-slim-buster
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "app.py"]
This Dockerfile specifies that our application runs on Python 3.8, it adds the current directory (which includes our Flask application and the trained model) to /app in the container, installs the necessary Python packages, and starts the Flask application when the container is launched.
After creating the Dockerfile, we can build the Docker image by running:
docker build -t my-model-server .
Once the Docker image is built, we can push it to a Docker registry such as Docker Hub with
docker push my-model-server.
Finally, we'll need to create a Kubernetes Deployment to deploy our model server in the Kubernetes cluster. Here's an example Deployment configuration:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-model-server
spec:
replicas: 3
selector:
matchLabels:
app: my-model-server
template:
metadata:
labels:
app: my-model-server
spec:
containers:
- name: my-model-server
image: my-model-server
ports:
- containerPort: 5000
volumeMounts:
- name: model-volume
mountPath: /models
volumes:
- name: model-volume
persistentVolumeClaim:
claimName: model-pvc
This Deployment configuration specifies that we want to run 3 replicas of our model server, each serving on port 5000. The model files are loaded from a Persistent Volume Claim named model-pvc, which should be set up to read from the location where our trained models are stored.
We can apply this Deployment with kubectl apply -f deployment.yaml, which will create the Deployment and start the model server pods.
By following these steps, we can deploy a trained machine learning model in a Kubernetes cluster, where it can be used to make predictions at scale.
Conclusion
In the rapidly evolving world of data science and machine learning, managing the diverse and complex workloads can be a daunting task. However, as we have explored in this article, Kubernetes presents a powerful and flexible platform for optimizing and managing machine learning workloads.
By leveraging the distributed nature of Kubernetes, we can achieve efficient utilization of resources, and thus speed up training of complex neural network models. Kubernetes Operators simplify the process of deploying and managing machine learning models, making it easy to handle updates, rollbacks, and auto-scaling. The use of a distributed storage solution like Ceph can greatly enhance data management capabilities, allowing for seamless data sharing and persistence across the cluster.
The application we built throughout this article serves as a simple example of how one might structure a machine learning workload in a Kubernetes environment. We walked through setting up a Kubernetes cluster, training a simple neural network model, and finally, deploying that model within a Kubernetes cluster.
While our application was relatively simple, the principles and techniques we discussed apply to much more complex machine learning workloads. With the extensive tooling and community support around Kubernetes, it's possible to scale up these concepts to handle production-grade machine learning applications.
However, it's worth noting that as with any technology, Kubernetes is not a silver bullet. It presents its own set of challenges and complexities and requires a certain level of expertise to manage effectively. Therefore, it's crucial to carefully evaluate your specific use case and requirements before deciding to adopt Kubernetes for your machine learning workloads.
Looking ahead, Kubernetes is poised to play an even more significant role in the machine learning field. With the advent of technologies like Kubeflow, a dedicated machine learning toolkit for Kubernetes, managing machine learning workloads on Kubernetes is becoming even more streamlined. Therefore, developing a strong understanding of Kubernetes and its principles is a valuable skill for any data scientist or machine learning engineer.
In conclusion, Kubernetes offers a compelling solution for optimizing machine learning workloads. By providing a robust, flexible, and scalable platform, it empowers data scientists and machine learning engineers to focus on the core task of building and refining models, rather than worrying about the intricacies of infrastructure management. As Kubernetes continues to evolve and improve, it's exciting to think about the new possibilities it will unlock in the machine learning domain.
Related Reading
- Kubernetes
- Infrastructure